The next thing to consider is how to connect two such processors together so that they can work on the same problem.
Below is a 'Simple Representaion of a Processor.' This will be used so later diagrams don't get too big.
Two connected processors can be represented as below.
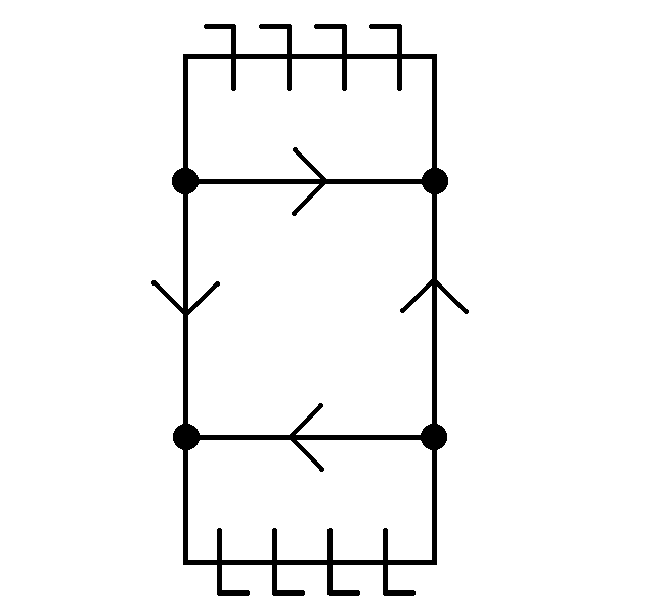
The latches and enabled buffers can be labeled to make it easier to refer to the parts, as below.
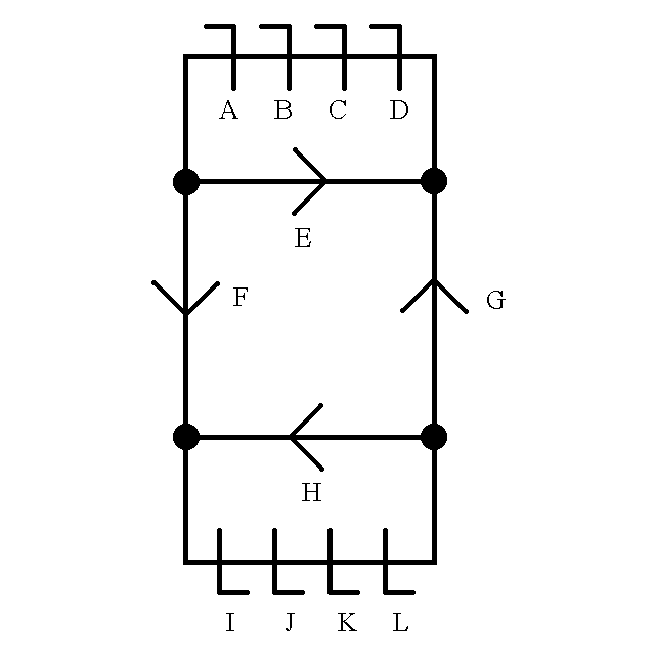
Suppose that latch L of the bottom processor has a state that is trying to get to latch D of the top processor (because the top processor has the data that the state in latch L wants to read). If latch D does not have valid data (a valid state with valid data bit (also called ‘valid state bit’) value 1), then, during the clock cycle, enable buffer G is enabled and data is copied from latch L, through buffer G, to latch D. Now suppose that latch A has valid data trying to reach latch D, but latch L does not have data trying to reach latch D. If latch D does not have valid data, then, during the clock cycle, enabled buffer E is enabled and data is copied from latch A, through buffer E, to latch D. Finally, suppose that both latch A and latch L have states trying to reach empty latch D. Then, latch L gets priority and the state in latch L gets copied, through buffer G to latch D.
(The timing for the computer is very simple and almost entirely consists of signals to just move data from latch to latch through buffers.)
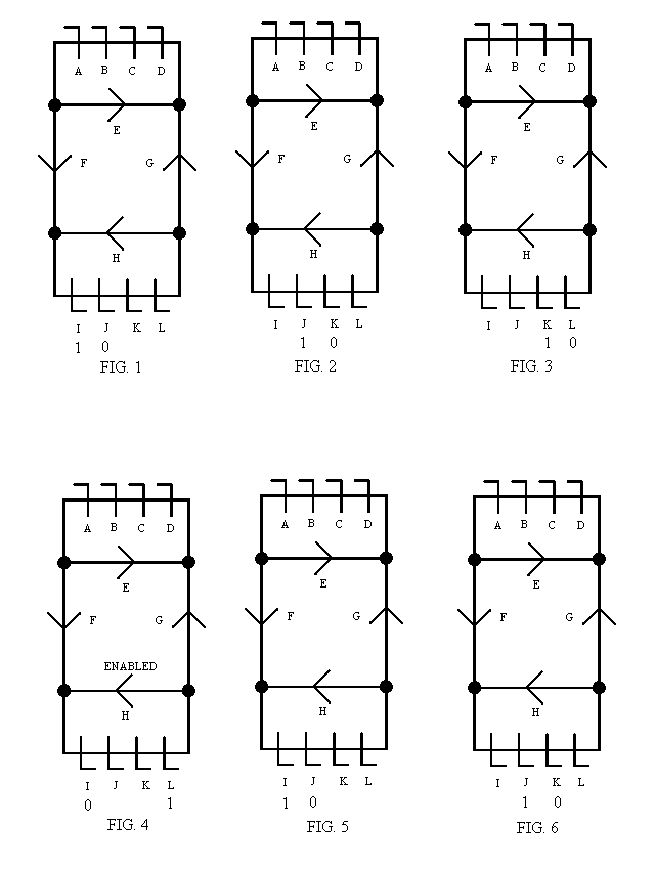
As an example, consider the movement through the processors of the state in the diagrams below.
The state (register values of a simulated microprocessor) starts out in the first latch of the bottom processor, latch ‘I’, in figure ‘FIG. 1’. To indicate this a ‘1’ is shown below latch ‘I’. To execute a step of an instruction in the bottom processor, the state must proceed through logic to latch J, then latch K, then latch L. The state is initially in latch I and is trying to get to latch J. The 1 below latch I indicates that there is a state in latch I. (The valid data bit in latch I would have value 1 to indicate this to the processor logic.) The 0 below latch J indicates that there is NOT a state in latch J. (The valid data bit in latch J would have a value of 0 to indicate this to the processor logic.) Therefore, when the clock lines go through a full cycle, the state is copied from latch I to latch J. The state passes through the logic not shown between latch I and latch J on its way from latch I to latch J. This bit of logic might decode the instruction in the selected instruction register (bits in the state).
There is logic (not shown) only between latch I and latch J and between latch J and latch K and between latch K and latch L in the bottom processor. Similarly, in the top processor there is logic (not shown) only between latch D and C and between latch C and B and between latch B and A. The not-shown logic blocks just described actually update the state (register values) just like a microprocessor would update its register values. There are no blocks of logic anywhere else (although there is a little logic to route the states).
In FIG. 2, latch J now has the state as indicated by the ‘1’ below latch J and latch K is empty as indicated by the ‘0’ below latch K. Therefore, during the next full clock cycle, the data is copied (through instruction processing logic) next from latch J to latch K.
The result is shown in FIG. 3 where the state (register values of a simulated microprocessor) is in latch K as indicated by the ‘1’ below latch K. Latch L is empty, so the data can be processed to latch L during the next full clock cycle.
In FIG. 4, the state is now in latch L and the instruction step has been completed. The state of a simulated microprocessor in latch I has been updated as indicated by the instruction step that was in the selected instruction register of the state.
As it happens, the next instruction step to be executed is a read (load) instruction step that copies data from the memory to the state (from the memory to a register). The memory is in the logic between latch J and K. The instruction in the state in latch L in FIG. 4 is therefore trying to get to latch I to begin executing the next instruction step with the bottom processor. Latch I is empty, as indicated by the 0 below latch I in FIG. 4, so enable buffer H is enabled allowing data to pass from latch L to latch I during the next full clock cycle.
In FIG. 5, the updated state is in latch I again, ready to execute the next instruction step.
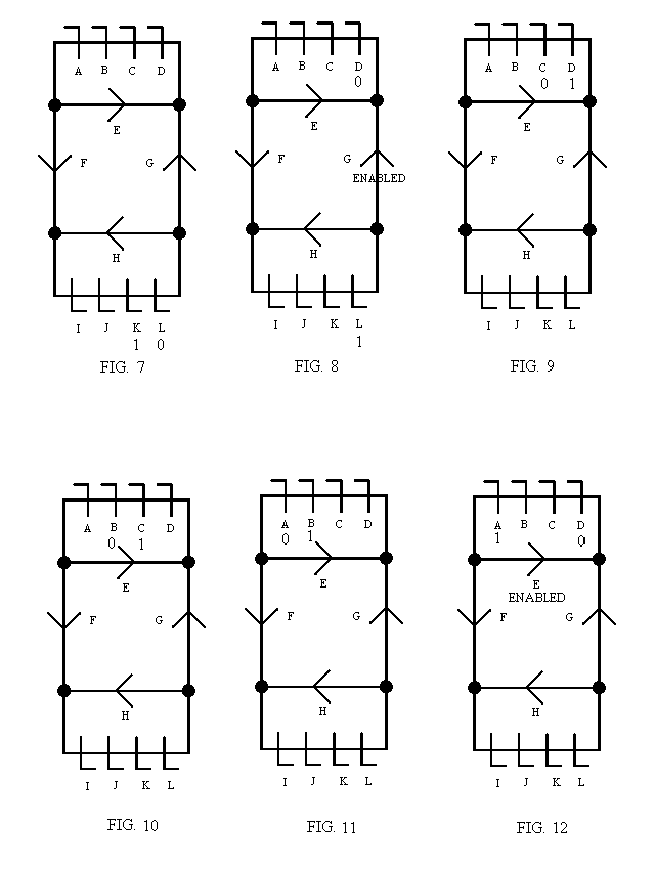
In FIG. 6, FIG. 7, and FIG. 8, the next instruction step is processed as the state goes from latch I to latch L through the logic (all the parts of a microprocessor) that executes an instruction step just as before.
In FIG. 8, the state in latch L is another read instruction step, but this time the address to be read indicates that the data is in the top processor’s memory. As it happens, latch D at the beginning of the top processor, does not have a state in it, as indicated by the ‘0’ below latch D, so during the next clock cycle, the state in latch L can travel through enabled buffer G to latch D.
In FIG. 9, the state is in latch D, ready to be processed by the top processor. Notice that the programmer did not have to indicate that another processor was to be used for the next instruction step. The bus logic detected that the read instruction step needed data in the top processor and directed the state that way. The programmer just had to indicate what address the data was to be read from. Therefore, the programmer, when using a single state, does not even have to be aware that more than one processor is being used. The programmer can assume that it is all one big block of memory (always, if the programmer is using only one state).
In FIG. 10, FIG. 11, and FIG. 12, the state is processed through the top processor and the read instruction step of data in the top processor’s memory is done.
In FIG. 12, the state is in latch A, the end of the top processor, and the next instruction step, perhaps a store (write) (from the state (register) to memory) is to write data to the memory of the top processor and latch D is empty. Therefore, during the next clock cycle, the state will be copied though enabled buffer E to latch D.
Four processors can be interconnected as below.
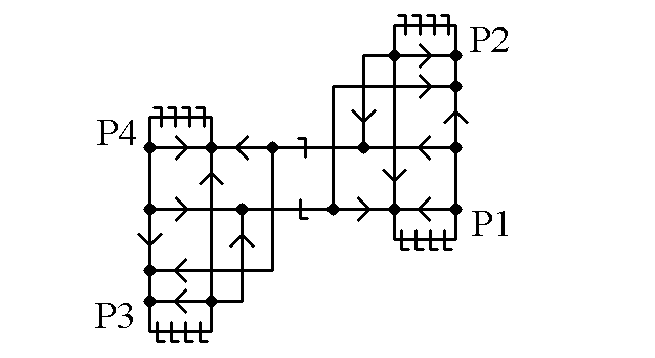
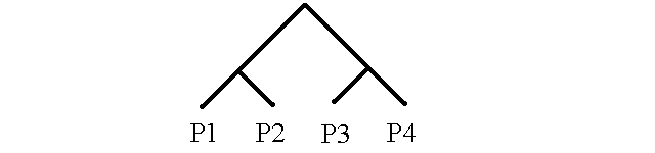
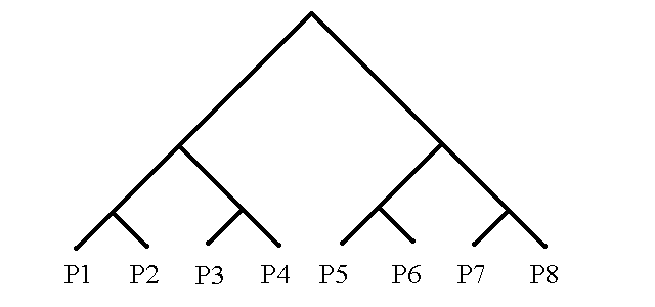
The processors, P1, P2, P3, and P4 are connected together on a binary tree as indicated below. Note that the processors are at the leaves (at the bottom of the tree), but are not at the ‘nodes’, where the branches branch (split).
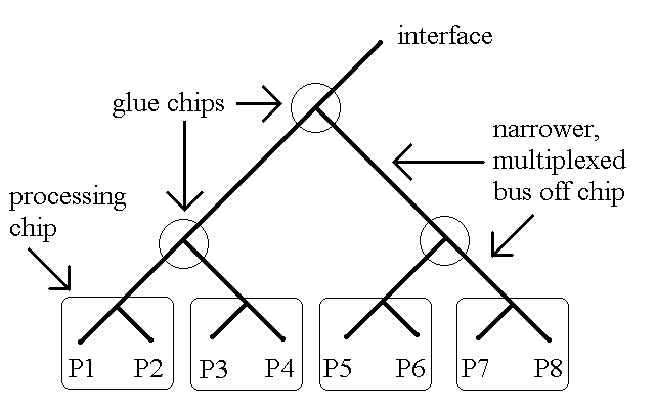
Any number of processors can be connected with a binary tree. Eight processors are interconnected below.
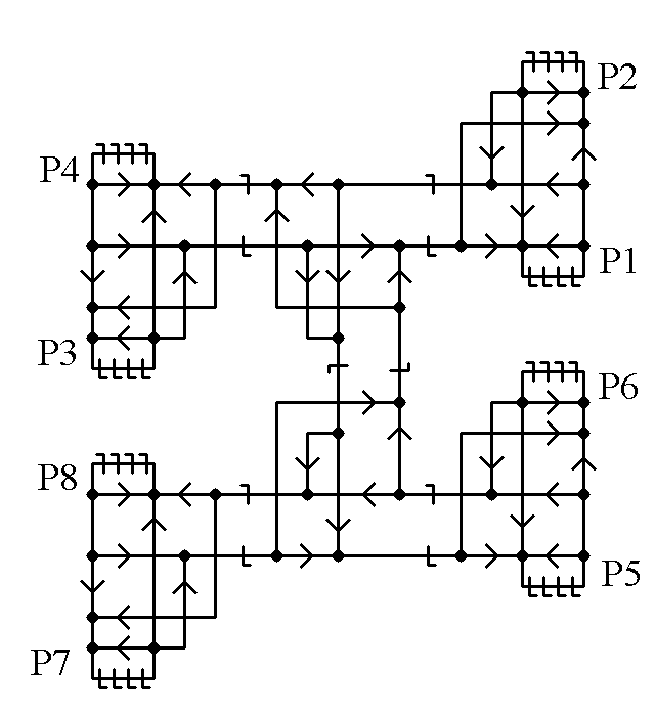
or, more briefly
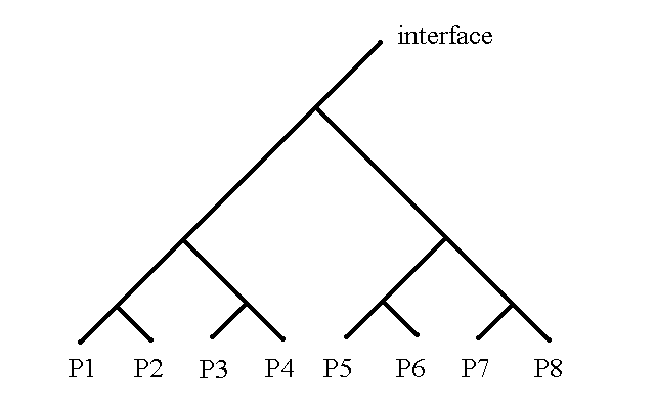
This whole computer can be just a coprocessor (helping a computer like in the book), so it needs a way to connect to the other processor. The interface to the other processor can be via the top of the binary tree as indicated below using the book computer's inputs and outputs to connect to the interface between processors.
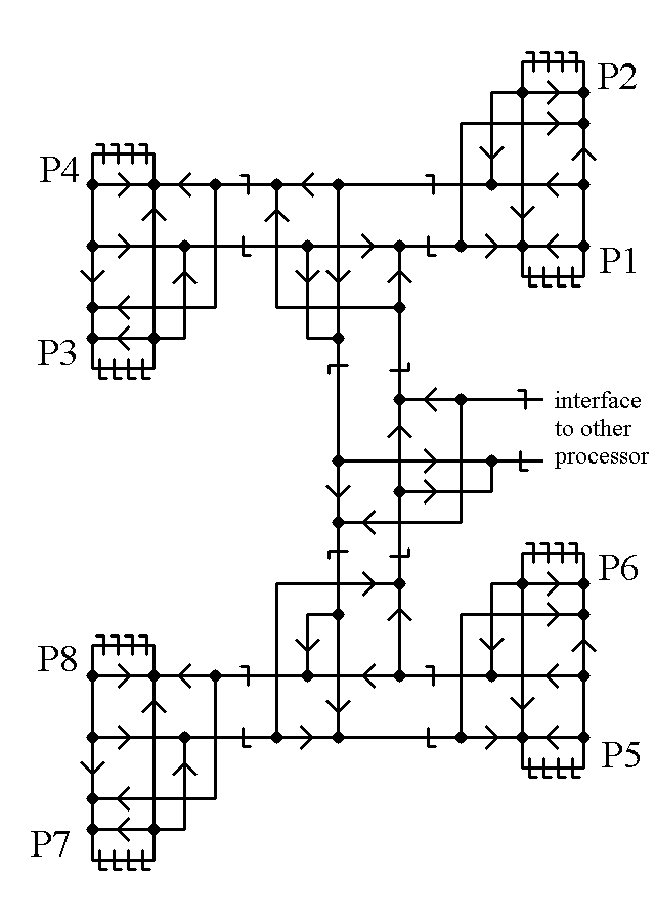
or, more briefly
On the way out of the processor, the next address to be read from or written to is examined. The higher address bits tell which processor is to be used next. Five bits are calculated from the processor address (higher address bits) that tell how far up the tree the state has to go before coming back down. Other wires carry the address bits, indicating the processor and indicate which branches to take on the way down the tree. These wires are besides the 256-bit state and valid state bit.
If there are so many processors that they won't all fit on one chip, then the chips are connected by 'glue chips,' so that the chips don't have too many wires sticking out. The data can be multiplexed (sent over fewer wires a few at a time) as indicated in the diagram below.